Building a Resilient Cloud Application: The Network Layout
This is the first of a series that I want to breakdown the different components of modern day applications that operate around the world, and has become easy to deploy with the cloud.
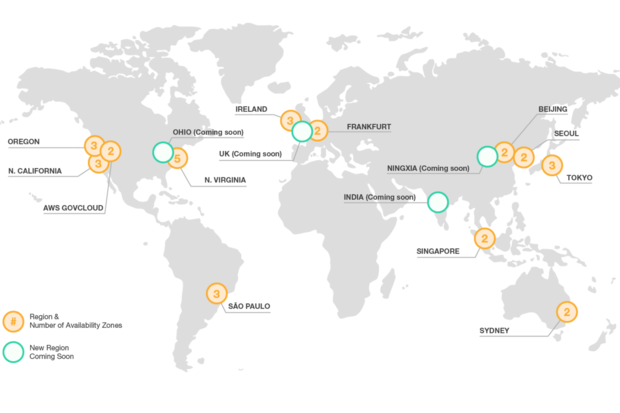
For example AWS has setup 16 different regions all over the world, from US-WEST-1 in Northern Calfornia, to US-EAST-2 in Ohio, all across the world to EU-CENTRAL-1 in Frankfurt to AP-SOUTH-1 in Mumbai.
For a full list check out their availability regions listed here.
Regions are responsible for isolating your application to a particular region. An application deployed to one region will not be available in another region. We use this principle to isolate failure and to have higher control of our systems which we'll talk about later.

The Network Layout
Regions
Around the world, the big cloud have graciously put the effort to build the infrastructure to host your applications in just about everywhere in the world. In order to organize a set of systems, each provider offers various "Regions" that you can set up your cluster.For example AWS has setup 16 different regions all over the world, from US-WEST-1 in Northern Calfornia, to US-EAST-2 in Ohio, all across the world to EU-CENTRAL-1 in Frankfurt to AP-SOUTH-1 in Mumbai.
For a full list check out their availability regions listed here.
Regions are responsible for isolating your application to a particular region. An application deployed to one region will not be available in another region. We use this principle to isolate failure and to have higher control of our systems which we'll talk about later.
Availability Zones
Within each region, there are typically further physically isolated data centers called Availability Zones. While there are still network connectivity between the Availability Zones, each zone is physically separated from one another. This allows further resiliency that if one location experiences natural or technical issues, it has other availability zones to fall back to. It is generally easy to split your resources across these availability zones with small performance drawbacks.
Typical Application Setup
Utilizing this infrastructure, companies around the world have been able to build globally accessible, fault-tolerant systems.
What you will usually find is that a company will have multiple application stacks running concurrently across multiple regions, for example one in Northern California and one in Frankfurt. Each stack should more or less self-sustainable in that it has all the services it needs to operate. Persistent data such as Databases may be access cross-region, but there are emerging technology that is pushing us towards a more completely isolated system. In each region, their application will be deployed to one or more Availability Zones for further separation.
Now the question lies, if you have multiple application stacks running around the world, how do you determine which one a user accesses? This is solved by fronting your application with a DNS service such as UltraDNS, or Route 53 in order to route traffic according to various rules to the server that you want. Strategies will be explained in a future post.
Typical Request Flow
1. Request is made to your application
2. The DNS service decides which region to send your request
3. The Region accepts the request, and send to a Load Balancer
4. The Load Balancer will decide which instance to send the request, which is in a specific Availability Zone
5. Your instance will handle the request and respond appropriately

Comments
Post a Comment